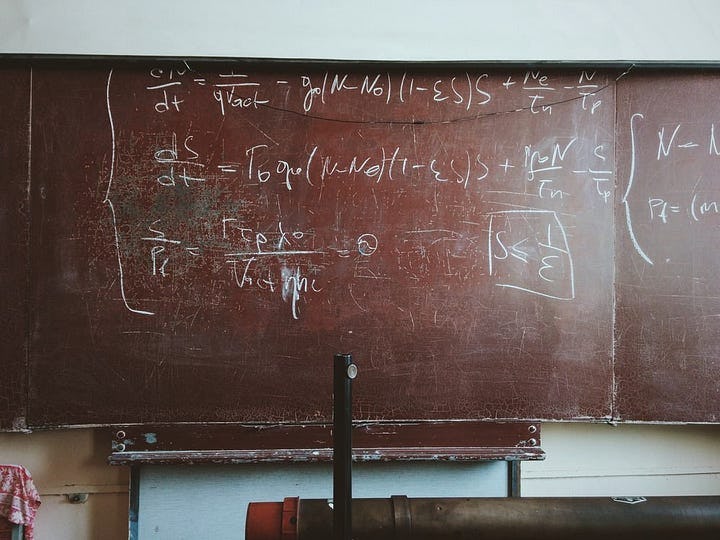
此篇文翻譯自筆者英文文章:A Deep Dive into Latent Dirichlet Allocation (LDA) and Its Applications on Recommender System
Latent Dirichelet Allocation(LDA)是一種主題建模演算法(topic modeling),廣泛使用於以無監督學習,探索語料庫中的隱含主題(latent topic)。它已被廣泛應用於各個領域,尤其是在自然語言處理和推薦系統中。
概論
LDA是語料/文檔的生成概率模型。它基於“詞袋” (bag-of-words)的假設,就是單詞和文檔都存在可替換性。也就是說,我們並不考慮文檔中的單詞順序或文檔的順序。
每個文檔由不同含量的主題所組成,而每個主題則是以不同字詞的分佈來表示。
每個文檔由不同含量的主題所組成 (https://www.youtube.com/watch?v=DWJYZq_fQ2A)
每個主題則是以不同字詞的分佈來表示。 (https://www.youtube.com/watch?v=DWJYZq_fQ2A)
在LDA的假設中,每個文檔中的主題進行採樣,然後對每個採樣主題中的單詞進行採樣來生成每個文檔。為了得到字詞和主題的正確機率分佈,我們可以使用 Gibbs Sampling, Maximum a Posteriori (MAP)或 Expectation Maximization (EM)訓練LDA。
板符號(Plate Notation)
為了更深入,讓我們談談LDA的板符號(Plate Notation)。在貝氏推論(Bayesian inference)中,Plate Notation是一種圖形表示表達對隨機變數採樣的重複過程的方式。每個板塊都可以看作是一個“迴圈”,其中,如板塊右下角所表示的符號代表該迴圈的次數。下圖表示LDA的板符號。
上圖可以分為兩個部分,上面的圖板指出,有K個主題,其字詞的狄利克雷分布 (Dirichlet distribution) 在單詞上由超參數β控制。同樣,下面的圖板描述了有M個文檔,每個文檔包含N個字詞。灰色的圓圈w代表觀察到的單詞,而白色圓圈代表不同的潛在變數。 z表示字詞w對應的主題,θ是主題在文檔上的狄利克雷分布,而θ被超參數⍺所控制。
生成過程 (Generative Process)
我們現在大致了解瞭了如何通過標牌符號生成文檔,讓我們用數學式子來表達它。
1. 對於i從1到M, 從狄利克雷分布抽取樣本θ θ_i〜Dir(⍺)
2. 對於k從1到K,從另一個抽取樣本φ狄利克雷分布φ_k〜Dir(β)
3. 對於i從1到M以及j從1到N,從多項式分佈中抽取樣本z_ij〜Multinomial(θ_i)和樣本w_ij〜Multinomial(φ_z_ij)
以《紐約時報》為例。首先,對於每個新聞文章,我們對整個文檔的主題分佈θ_i以及每個主題上的單詞分佈φ_k進行抽樣。然後,對於文檔中的每個字詞j,我們從給定的主題分佈Multinomial(θ_i)抽樣主題z_ij,接著,在對單詞分佈Multinomial(φ_z_ij)對字詞進行抽樣得到w_ij。下圖顯示了這個過程。
狄利克雷分布
我們剛剛都在把狄利克雷分布當作黑匣子,而沒有說明他是怎麼樣的一個函數。讓我們簡要地簡要介紹一下狄利克雷分布。 k維狄利克雷分布是由k維參數向量Alpha控制。下面我們顯示狄利克雷分布的3維范例。基本上alpha越大,分佈越趨向中心。這種分佈讓模型能夠有非常大的自由度決定詞/主題相對於主題/文檔相關的比例,因為某些主題/文檔可能與許多組詞/主題相關聯,而其他主題/文檔可能只和少部分詞/主題有關係。
訓練模型
學習LDA模型的問題我們稱之為“推理”問題。也就是說,給定觀察變數w以及超參數⍺和β,我們如何估計潛在變數的後驗機率(posterior probability)。
然而分母的部分因為計算他所需要的積分並沒有閉合解(closed form solution),簡單來說就是太複雜無法計算,如以下所示:
因此我們必須用估計的方式得到此解,而吉布斯抽樣(gibbs sampling)是最常用的方法之一。
吉布斯抽樣
使用吉布斯抽樣,我們可以避免直接計算難解積分。簡單來說,我們想對p(w|⍺,β)進行抽樣來估計分佈,但是我們不能直接這樣做。所以利用吉布斯抽樣,在每一次循環迭代中,我們可以分別對每一個潛在變數抽樣,同時固定所有其他變數。這樣,我們可以得到後驗分佈p(θ, z, φ|w, ⍺, β)。 每次迭代中,我們對θ, z 和φ進行抽樣,並且固定為所有其他變量,如以下所示:
對於i從1到MaxIter (最大迴圈數):
- 抽樣θ_{i}〜p(θ| z = z_ {i-1}, φ=φ_{i-1} w, ⍺, β)
- 抽樣z_ {i}〜p(z |θ=θ_{i}, φ=φ_{i-1} w, ⍺, β)
- 抽樣φ_{i}〜p(φ|θ=θ_{i}, z = z_ {i} w, ⍺, β)
由於早期迭代中的樣本分佈比較不穩定,因此我們捨棄前面幾輪的抽樣,這些被捨棄的樣本我們稱之為「burn-in」。
LDA on Recommender System
LDA 常用在推薦系統的兩個子領域:
- 協同過濾 (collaborative filtering)
- 基於內容推薦(content-based recommender system)
協同過濾
LDA應用在基於物品的協同過濾 (item-based CF)時, 物品和使用者 可以被比擬為前面所述之 文檔和字詞 (基於使用者的協同過濾則會相反). 也就是說,每個物品對應到一個使用者群組的分佈,而每個使用者群組則由不同比例的使用者所組成。利用LDA,我們可以找出使用者和物品的潛在關係。
基於內容推薦
第二個LDA在推薦系統上的應用是基於內容推薦,而這個應用還蠻直觀的。有別於以往直接使用TF-IDF所得到的個物品的表徵,我們可以利用LDA來抽取潛在物品特徵向量。底下我們示範一段如何用文檔訓練LDA以及如何利用LDA預測。
總結
在這篇文章中,我們從討論了LDA的概論以及LDA背後數學的細節,我們也討論了LDA如何應用在推薦系統中,並且示範了一些程式碼該如何使用它,我希望這篇文章是對你有幫助的,我們下次見:)
引用
- Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. Journal of machine Learning research, 3(Jan), 993–1022.
- Alexander, S. Latent-Variable Modeling for Natural Language
- Scott, S LDA Algorithm Description
- Thushan, G. Intuitive Guide to Latent Dirichlet Allocation